Open the amazon emr console at console. aws. amazon. com/elasticmapreduce/. choose create cluster, go to advanced options. for software configuration, choose emr release emr-5. 1. 0 or later. choose flink as an application, along with any others to install.
Deep Dive Of Flink Spark On Amazon Emr February Online Tech
Amazon emr is the industry-leading cloud big data platform for processing vast amounts of data using open source tools such as apache spark, apache hive, apache hbase, apache flink, apache hudi, and presto. amazon emr makes it easy to set up, operate, and scale your big data environments by automating time-consuming tasks like provisioning capacity and tuning clusters. Resource "aws_emr_cluster" "cluster" { name = "emr-test-arn" release_label are : flink hadoop hive mahout pig spark and jupyterhub (as of emr . Geisinger's referring provider portal. complete your organization's one-time enrollment. then, add your users.
With Integration Complete Cloudera Relaunches Sql Stream Builder
Use Apache Flink On Amazon Emr Aws Big Data Blog
Apache flink is a streaming dataflow engine that you can use to run real-time stream processing on high-throughput data sources. flink supports event time . Now let's look at how we can use flink on amazon web services (aws). amazon provides a hosted hadoop service called elastic map reduce (emr).
Tens of thousands of customers use amazon emr to run big data analytics applications on frameworks such as apache spark, hive, hbase, flink, hudi, and presto at scale. emr automates the provisioning and scaling of these frameworks and optimizes performance with a wide range of ec2 instance types to meet price and performance requirements. As edge devices generate ever-larger data quantities, data management specialists are offering new frameworks to reduce reliance on cloud services by embedding intelligence to perform storage and analysis locally. You can also run other popular distributed frameworks such as apache spark, hbase, presto, and flink in amazon emr, and interact with data in other aws . Craig foster is a big data engineer with amazon emr. apache flink is a parallel data processing engine that customers are using to build real time, big data applications. flink enables you to perform transformations on many different data sources, such as amazon kinesis streams or the apache cassandra database. it provides both batch and streaming apis.
Run several jobs in parallel in same emr cluster?. hello i'm running flink over amazon emr and i'm trying to send several different batch jobs . Aug 11, 2016 real-time data processing apache flink and amazone emr. by ruben tytgat. this post puts the spotlight on amazon emr (elastic . Debezium flink emr. hi, i'm trying to set up flink with debezium cdc connector on aws emr, however, emr only supports flink 1. 10. 0, whereas debezium connector arrived in flink 1. 11. 0, from looking. Apache flink is included in the amazon emr distribution and has been installed on the cluster. to start the flink jobmanager, execute the following command.
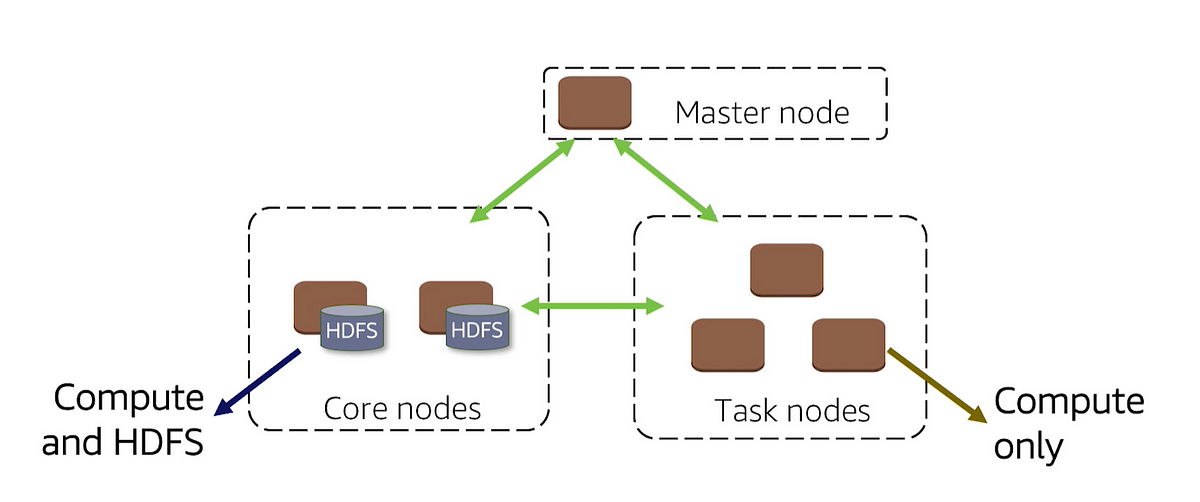
For security reasons, when using emr-managed security groups, these web sites are only available on the master node's local web server, so you need to connect to the master node to view them. for more information, see connect to the master node using ssh. Feb 27, 2017 real-time stream processing on emr: apache flink vs apache spark flink emr streaming keith steward, ph. d. specialist (emr) solution architect aws . Flink recently introduced support for obtaining aws credentials from the role that is associated with an emr cluster. enable this functionality in the flink application source code by setting the aws_credentials_provider property to auto and by omitting any aws_access_key_id and aws_secret_access_key parameters from the properties object. 也可以使用 flink api 更改某些配置。有关更多信息,请参阅 flink 文档中的 基本 api 概念。. 使用 amazon emr 版本 5. 21. 0 以及更高版本,您可以覆盖集群配置,并为运行的集群中的每个实例组指定更多配置分类。.
Apache flink is a parallel data processing engine that customers are using to build real time, big data applications. flink enables you to perform transformations on many different data sources, such as amazon kinesis streams or the apache cassandra database. it provides both batch and streaming apis. Install flink on emr cluster after creating your cluster, you can connect to the master node and install flink: go the the downloads page and download a binary version of flink matching the hadoop version of your emr cluster, e. g. hadoop 2. 7 flink emr for emr releases 4. 3. 0, 4. 4. 0, or 4. 5. 0. Note: you don’t have to configure this manually if you are running flink on emr. flink provides two file systems to talk to amazon s3, flink-s3-fs-presto and flink-s3-fs-hadoop. both implementations are self-contained with no dependency footprint, so there is no need to add hadoop to the classpath to use them.
Flink on emr cannot access s3 bucket from “flink run” command. 0. where to specify spark configs when running spark app in emr cluster. 0. running flink 1. 5 on yarn. 1. configure flink rest api on amazon flink emr emr. 0. apache flink installation 1. 6. 2 on mac with homebrew. 0. There are several ways to interact with flink on amazon emr: through amazon emr steps, the flink interface found on the resourcemanager tracking ui, and at the command line. all of these also allow you to submit a jar file of a flink application to run. Apache flink is a streaming dataflow engine that you can use to run real-time stream processing on high-throughput data sources. flink supports event time semantics for out-of-order events, exactly-once semantics, backpressure control, and apis optimized for writing both streaming and batch applications. You have requested emergency access to areas of emr-link containing protected health information. all actions will be logged for reporting purposes. log out to end emergency access. click ok to be granted access.
Apache flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. it supports a wide range of highly customizable connectors, including connectors for apache kafka, amazon kinesis data streams elasticsearch, and amazon simple storage service (amazon s3). Configuring flink on flink emr an emr cluster with multiple master nodes the jobmanager of flink remains available during the master node failover process in an emr cluster with multiple master nodes. beginning with amazon emr version 5. 28. 0, jobmanager high availability is also enabled automatically. no manual configuration is needed. In october, cloudera acquired eventador, which developed a sql-based streaming data analysis solution based on apache flink. with the work to integrate that product with the cloudera data platform (cdp) complete, the company today re-launched it as. Apache flink is an open-source project that is tailored to stateful computations over unbounded and bounded datasets. flink addresses many of the challenges that are common when analyzing streaming data by supporting different apis (including java and sql), rich time semantics, and state management capabilities.
